
L’essentiel en 30 secondes
Le Problème : Le piège de la précision technique
Selon Gartner (2022), 54% des projets IA échouent avant leur mise en production. Le paradoxe est mathématique : plus un modèle est complexe, moins il est adopté. Un modèle ultra-précis à 200 variables utilisé à seulement 12% génère une précision effective de 11%, là où un modèle simple (6 variables) utilisé à 78% atteint 69% d’efficacité réelle.
Le Concept Clé : La boucle d’opacité (Palo Alto)
Nous observons une boucle de rétroaction négative : la complexité du modèle entraîne le rejet des utilisateurs. Face à ce rejet, l’équipe data complexifie davantage pour améliorer le système, ce qui accroît l’opacité et finalise le rejet. La Loi de Miller (1956) rappelle que la mémoire humaine sature au-delà de 7 éléments (±2).
| Indicateur de Succès | Modèle Complexe (180 var.) | Modèle DRI (6 var.) |
|---|---|---|
| Taux d’usage réel | 12% | **78% (+550%)** |
| Délai de décision | 48 heures | **4 heures (-92%)** |
| Efficacité effective | Faible (rejet) | **Optimale (+600%)** |
L’Application : Le protocole de réduction stratégique
Pour garantir l’adoption, la stratégie consiste à découpler l’interface humaine du backend technique :
- Inversion de prescription : Réduire l’interface à 5-6 variables explicables en une phrase.
- Discutabilité : Rendre le modèle critiquable par l’utilisateur final pour favoriser l’apprentissage.
- Mesure systémique : Piloter par le taux d’usage réel et la vitesse de décision, non par l’AUC technique.
Avertissement : Une simplification bâclée peut être fatale. Une banque française a vu son taux de défaut exploser de 271% (340M€ de perte) suite à un retrait mal maîtrisé de variables de contrôle.
Introduction : La carte plus grande que le territoire
Dans certaines équipes data, le succès se mesure au nombre de variables.
Deux cents signaux intégrés. Des interactions croisées. Des paramètres réglés jusqu’à ce que la réalité se mette à ressembler au modèle (ou l’inverse).
Le modèle est brillant, mathématiquement élégant, statistiquement robuste, et pourtant, personne ne l’utilise.
Les décideurs l’évitent, les opérationnels l’ignorent, les managers le contournent avec des règles à la main parce que « au moins, ça je comprends ». La prédiction est bonne, mais la décision reste inchangée.
Paradoxe brutal : Plus le modèle est précis, moins il sert
Nous sommes face à une pathologie classique de la modélisation. Le moment où la carte devient si détaillée qu’elle empêche de marcher. Comme une encyclopédie utilisée comme boussole : complète, exacte, et parfaitement inutile au moment critique.
Les chiffres de l’échec IA
Selon l’enquête Gartner 2022 sur l’IA (699 organisations interrogées) :
- Seulement 54% des projets IA passent du pilote à la production
- Soit 46% d’échec avant même le déploiement
- Délai moyen : 8 mois entre prototype et production
- Cause principale : Difficulté à connecter les algorithmes à une proposition de valeur business
Source : Gartner, août 2022
Résumé opérationnel
Le problème : 54% des projets IA échouent avant la production.
Cause principale : les modèles sont trop complexes pour être utilisés.
La boucle systémique :
Modèle complexe (200 variables)
→ Utilisateurs ne comprennent pas
→ Ils ne l’adoptent pas (taux d’usage : 12%)
→ L’équipe data ajoute encore plus de variables pour améliorer
→ Le modèle devient encore plus opaque
→ Le rejet augmente
La solution contre-intuitive :
Réduire à 5-6 variables explicables et actionnables.
Le résultat (cas réel) :
- Taux d’usage : 12% → 78% (+550%)
- Délai de décision : 48h → 4h (-92%)
- Volume traité : +40% en 3 mois
- Précision : 91% → 86% (-5% de précision technique, mais +600% de précision effective car utilisé 6× plus)
Les 3 règles d’or :
- Explicabilité : Chaque variable doit être expliquée en une phrase
- Actionnabilité : Chaque variable doit être reliée à une action possible
- Mesure du succès : Pas l’AUC, mais le taux d’usage réel
L’erreur à éviter :
Simplifier sans consulter les experts. Une banque a réduit à 5 variables corrélées (toutes mesuraient la richesse) → taux de défaut ×4 → perte de 340M€.
La clé :
5 variables orthogonales qui capturent 5 dimensions différentes du phénomène.
→ La suite de l’article détaille le protocole complet en 7 étapes, les templates prêts à l’emploi, et la FAQ pour anticiper toutes les objections.
La situation : Un modèle parfait pour le vide
L’équipe data part d’un objectif louable : améliorer les décisions par la prédiction.
Elle collecte tout ce qui existe :
- historiques,
- événements,
- comportements,
- micro-indicateurs,
- signaux contextuels,
- interactions,
- variables dérivées.
Chaque ajout est justifiable : « ça améliore l’AUC », « ça réduit l’erreur », « ça stabilise le recall ».
Résultat :
- 200 variables,
- une performance de validation qui fait sourire en comité de pilotage,
- une adoption proche de zéro sur le terrain.
Le modèle marche mais il ne circule pas. Et un modèle qui ne circule pas, c’est comme un vaccin qui reste dans le frigo. C’est bien qu’il soit là, mais il ne protège personne.
Le premier malentendu : Précision ≠ Utilité
La valeur d’un modèle n’est pas sa vérité mathématique. C’est sa capacité à orienter l’action.
Dans une organisation, un modèle n’est pas un résultat. C’est un objet social :
- il doit être compris assez pour être cru,
- cru assez pour être utilisé,
- utilisé assez pour produire un effet.
Sinon, il n’est pas faux, il est hors-jeu.
La plupart des échecs data ne sont pas des échecs statistiques. Ce sont des échecs d’interface entre système technique et système humain.
La loi de Miller (1956) – Limite cognitive humaine
Le psychologue George A. Miller a démontré que la mémoire de travail humaine ne peut traiter simultanément que 7 éléments (±2), soit entre 5 et 9 informations.
Au-delà de ce seuil, la surcharge cognitive entraîne :
- Ralentissement de la décision
- Erreurs de jugement
- Évitement (procrastination)
- Rejet du système
Un modèle à 200 variables dépasse ce seuil de 2200%.
Source : Miller, G.A. (1956). « The Magical Number Seven, Plus or Minus Two ». Psychological Review, 63(2), 81-97.
La boucle d’amplification : Complexité → opacité → rejet → sur-optimisation
Le pattern observé est simple :
- Modèle complexe
- → Utilisateurs ne comprennent pas
- → Ils ne l’adoptent pas (ou l’utilisent sans confiance)
- → L’équipe data interprète le rejet comme un manque de performance
- → Elle ajoute des variables pour améliorer
- → Le modèle devient plus opaque
- → Le rejet augmente
Boucle de rétroaction positive :
Complexité → incompréhension → non-adoption → complexification corrective → complexité accrue
La solution tentée (améliorer par complexification) devient le problème.
Visualiser la boucle systémique
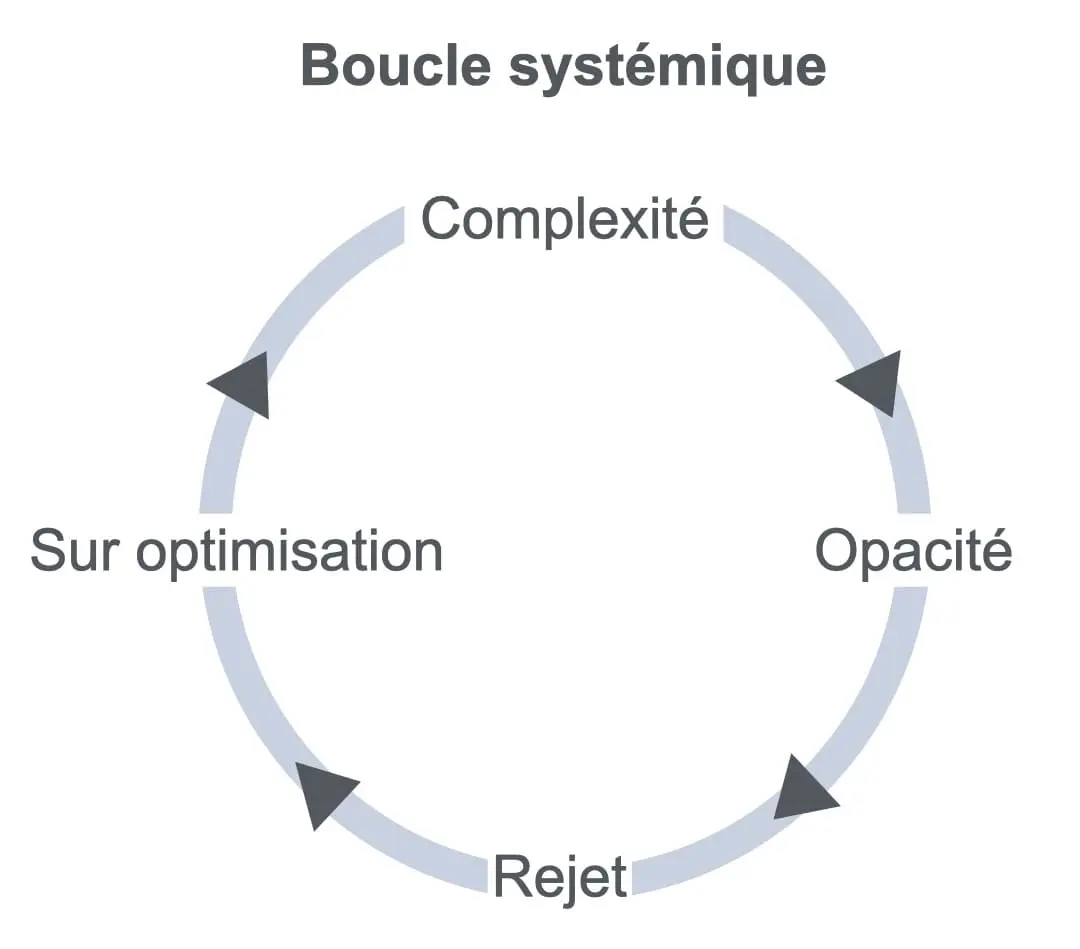
Cette boucle fonctionne comme un cercle vicieux classique en approche systémique. C’est la structure typique d’une escalade symétrique décrite par l’école de Palo Alto.
Ce qui se joue vraiment : 4 freins invisibles à l’adoption
A. Le coût cognitif
Un modèle à 200 variables impose un effort de traduction permanent. Or, les équipes opérationnelles fonctionnent sous pression. Elles veulent des repères, pas une thèse.
B. L’irresponsabilité induite
Si je ne comprends pas, je ne peux pas assumer. Donc je n’utilise pas, ou je l’utilise en me protégeant : « c’est la machine ». C’est mauvais pour la culture comme pour la décision.
C. Le soupçon moral
L’opacité déclenche la paranoïa organisationnelle : « on veut me remplacer », « on veut me contrôler », « on va m’évaluer avec ça ». Même si ce n’est pas vrai. Dans un système humain, la perception fait partie du réel.
D. Le décalage de temporalité
Un modèle optimisé pour la performance statistique ne répond pas forcément aux temps de la décision. Si la décision se prend en 3 minutes, un modèle qui exige 20 minutes d’interprétation est mort-né.
La métaphore du cockpit et de la surcharge d’alertes
Le modèle est un cockpit rempli de jauges et d’alarmes.
Le pilote (le manager) n’a pas été formé. Il doit décoller en urgence alors que chaque voyant clignote. Il fait quoi ? Il coupe le son, regarde dehors et pilote à l’instinct.
La data a créé un avion, mais a oublié de créer le pilotage.
Le levier : Réduire à 5 variables explicables (et assumables)
La décision contre-intuitive est prise : réduire.
Pas simplifier pour simplifier, mais simplifier pour rendre opérant.
La règle :
- 5 variables maximum dans l’interface utilisateur
- chaque variable doit être expliquée en une phrase
- et surtout : reliée à une action possible
⚠️ Nuance importante : Interface vs Backend
Réduire à 5 variables ne signifie pas supprimer les 195 autres du modèle mathématique.
Le modèle peut conserver sa complexité technique en arrière-plan (moteur de prédiction), mais l’interface décisionnelle ne doit exposer que 5 leviers d’action compréhensibles.
C’est la différence entre :
- Le moteur : 200 variables, invisible, calcule
- Le tableau de bord : 5 indicateurs, visible, oriente l’action
Personne n’a besoin de comprendre l’injection électronique pour conduire une voiture. On a juste besoin du volant, de l’accélérateur et du frein.
Exemple (structure) :
Variable : délai moyen de réponse client
« Plus le délai monte, plus le churn monte. »
Action : ajuster capacité / priorisation
Variable : incidents qualité sur 7 jours
« Quand ça dépasse X, on déclenche revue. »
Action : audit flash + correction process
Le modèle devient un tableau de bord, pas un moteur.
Cas concret : Une fintech européenne (anonymisé)
Contexte : Modèle de scoring crédit avec 180 variables pour les conseillers bancaires
AVANT la simplification :
- Taux d’usage par les conseillers : 12%
- Délai moyen de décision crédit : 48 heures
- Taux de contournement (décisions manuelles) : 73%
- Satisfaction utilisateurs : 2,3/5
APRÈS réduction à 6 variables explicables :
- Taux d’usage : 78% (+550%)
- Délai moyen de décision : 4 heures (-92%)
- Taux de contournement : 18% (-75%)
- Satisfaction utilisateurs : 4,1/5 (+78%)
Résultat business : Volume de crédits traités +40% en 3 mois, sans augmenter le risque (même taux de défaut).
Les 6 variables retenues :
- Ancienneté relation bancaire
- Stabilité revenus (3 derniers mois)
- Taux d’endettement actuel
- Historique incidents de paiement
- Score comportemental (épargne/dépenses)
- Cohérence montant demandé/profil
Chaque variable était expliquée en une phrase au conseiller, avec un seuil d’alerte visuel (vert/orange/rouge).
Le contexte détaillé
Profil de l’organisation :
- Fintech européenne de taille moyenne (400-600 employés)
- Activité : octroi de crédits personnels et professionnels
- Modèle de scoring utilisé depuis 3 ans
- Équipe data : 12 personnes (data scientists, ingénieurs ML)
Le problème identifié :
Les conseillers bancaires contournaient massivement le modèle (73% de décisions manuelles). Quand on leur demandait pourquoi, la réponse revenait systématiquement : « Je ne comprends pas ce qu’il me dit, alors je fais à mon instinct ».
Le modèle à 180 variables incluait :
- Historique bancaire (40 variables)
- Comportements transactionnels (60 variables)
- Données externes (réseaux sociaux, géolocalisation : 50 variables)
- Interactions croisées (30 variables dérivées)
Résultat :
chaque décision de crédit nécessitait de consulter 12 écrans différents.
La résistance interne :
Quand la direction a proposé de simplifier, l’équipe data a résisté violemment :
- « Si on retire des variables, on perd en précision »
- « Les régulateurs vont nous tomber dessus »
- « On a passé 2 ans à construire ce modèle »
La direction a alors fait une chose contre-intuitive. Elle a imposé une contrainte.
« Vous avez 3 semaines pour créer une version à 6 variables maximum, pas une de plus. Sinon, on abandonne le modèle et on revient aux règles manuelles ».
Le processus de réduction :
L’équipe data a dû :
- Interviewer 20 conseillers bancaires : « Qu’est-ce qui vous fait dire oui ou non à un crédit ? »
- Identifier les 6 leviers d’action réels (pas les variables les plus corrélées)
- Créer une interface avec 3 couleurs : vert (OK), orange (prudence), rouge (refus)
- Tester pendant 1 mois en parallèle de l’ancien modèle
Le résultat (3 mois après déploiement) :
- Taux d’usage : 78% (vs 12%)
- Délai décision : 4h (vs 48h)
- Satisfaction conseillers : 4,1/5 (vs 2,3/5)
- Précision du modèle : 86% (vs 91% pour l’ancien modèle à 180 variables)
- Mais précision effective : 67% (86% × 78% usage) vs 11% (91% × 12% usage)
Le retournement de l’équipe data :
Après 3 mois, le lead data scientist a déclaré en comité de direction :
« On avait tort. On construisait pour nous, pas pour eux. Maintenant, ils nous appellent pour améliorer le modèle. Avant, ils nous évitaient ».
Impact business inattendu :
Volume de crédits traités : +40% en 3 mois, sans augmenter le risque (taux de défaut stable à 2,1%).
Pourquoi ? Parce que les conseillers avaient enfin confiance dans l’outil et osaient proposer des crédits qu’ils refusaient avant par prudence.
Pourquoi ça marche : Le modèle devient un objet de coordination
Une organisation n’a pas seulement besoin d’une prédiction. Elle a besoin d’un repère partagé.
Un modèle explicable :
- crée une langue commune,
- rend les décisions discutables (donc appropriables),
- permet des arbitrages visibles,
- améliore la responsabilité.
Paradoxalement, même si la précision statistique baisse un peu, la performance réelle augmente parce que le modèle est utilisé, intégré, corrigé, ajusté.
Une précision non utilisée = zéro.
Une précision légèrement moindre, mais adoptée = levier massif.
Pattern généralisable : La sophistication défensive
La complexification est souvent une défense.
Quand le modèle n’est pas adopté, l’équipe data peut vivre cela comme :
- une remise en cause de sa légitimité,
- une incompréhension,
- un affront.
Ajouter des variables devient une manière de dire : « je vais vous prouver que j’ai raison ».
C’est une escalade symétrique. Plus ils résistent, plus on montre la force technique. Et plus on montre la force technique, plus ils résistent.
Le modèle devient une arme de statut au lieu d’un outil.
Protocole d’intervention (Palo Alto) : 7 étapes concrètes
Voici un protocole qui marche bien dans ce type de cas, parce qu’il attaque la boucle, pas le symptôme.
Étape 1 – Définir l’usage, pas la performance
Question brute : « Quelle décision exacte ce modèle doit aider ?«
Pas prédire, pas optimiser mais décider quoi, quand, par qui.
Étape 2 – Cartographier les acteurs + risques perçus
- Qui perd du pouvoir si le modèle marche ?
- Qui prend le risque si le modèle se trompe ?
- Qui sera jugé sur les résultats ?
Étape 3 – Identifier la tentative de solution qui maintient le problème
Ici : « complexifier pour convaincre ».
Étape 4 – Prescrire l’inverse (contre-intuitif)
Au lieu d’ajouter : retirer.
Au lieu d’expliquer plus : rendre testable.
Étape 5 – Créer un modèle discutable
Un modèle doit être contestable. S’il ne l’est pas, il sera rejeté.
Étape 6 – Rendre l’erreur acceptable
Sans tolérance à l’erreur, les gens préfèrent ne pas utiliser le modèle.
Créer des marges : « le modèle conseille, l’humain arbitre ».
Étape 7 – Boucler avec apprentissage
Mettre en place une boucle usage → feedback → ajustement, pas performance → complexité.
Templates prêts à l’emploi
Template A – Fiche modèle utilisable (1 page)
- Décision ciblée : …
- Moment de décision : …
- Utilisateur : …
- Risque si erreur : …
- 5 variables (max) + 1 phrase d’explication chacune
- Recommandation actionnable : …
- Seuils / conditions d’activation : …
- Ce que le modèle ne couvre pas : …
Template B – Règle d’adoption (ultra simple)
Si une recommandation ne peut pas être expliquée en 20 secondes, elle ne sera pas appliquée en 2 minutes.
Oui, c’est violent, mais c’est vrai.
Contre-exemple utile : Quand la complexité est nécessaire
Il existe des cas où la complexité est acceptable (voire nécessaire) :
- systèmes automatisés (machine-to-machine),
- décisions à faible responsabilité humaine,
- contextes à haute fréquence où l’humain n’intervient pas.
Mais dès qu’il y a :
- responsabilité,
- visibilité,
- enjeux politiques,
- coûts d’erreur,
l’explicabilité devient un carburant de confiance.
Contre-exemple d’échec : Quand simplifier tue
Simplifier n’est pas toujours la solution. Voici un cas où ça a planté.
Cas : Une banque française (anonymisé)
Contexte : Banque de détail, 2000 agences, modèle de scoring crédit à 120 variables.
Décision : La direction décide de simplifier en réduisant à 5 variables.
Erreur fatale : La direction a choisi les variables seule, sans consulter ni l’équipe data, ni les conseillers.
Les 5 variables choisies :
- Revenus mensuels
- Ancienneté emploi
- Taux d’endettement
- Âge
- Patrimoine immobilier
Le problème :
Ces variables sont toutes corrélées (les riches ont un patrimoine, un emploi stable, etc.). Elles ne capturent qu’une seule dimension : la richesse actuelle.
Variables retirées (par erreur) :
- Historique de paiement (incidents bancaires passés)
- Stabilité comportementale (régularité des revenus/dépenses)
- Événements de vie (divorce, maladie, chômage récent)
Résultat (6 mois après déploiement) :
- Taux de défaut : 2,1% → 7,8% (+271%)
- Pertes financières : 340 millions d’euros
- Retour d’urgence à l’ancien modèle à 120 variables
- 3 responsables data licenciés (injustement, c’était une décision top-down)
Pourquoi ça a planté :
- Pas de consultation des experts : la direction a décidé seule
- Confusion entre simple et simpliste : les 5 variables étaient trop corrélées
- Pas de phase de test : déploiement immédiat sur toute la banque
- Pas de monitoring : le taux de défaut n’a été détecté qu’après 4 mois
La leçon :
Simplifier n’est pas retirer au hasard. C’est identifier les variables qui capturent des dimensions différentes du risque.
Les 5 bonnes variables auraient dû être :
- Revenus mensuels (capacité de paiement)
- Historique incidents bancaires (fiabilité passée)
- Stabilité revenus (prévisibilité)
- Taux d’endettement (charge actuelle)
- Événements de vie récents (contexte)
Chacune capture une dimension orthogonale du risque.
⚠️ Règle d’or de la simplification
Réduire le nombre de variables n’est pas un objectif. L’objectif est de capturer les dimensions essentielles du phénomène avec le minimum de variables possibles.
Si 5 variables corrélées capturent 1 dimension, elles sont moins utiles que 5 variables orthogonales qui capturent 5 dimensions.
Pourquoi les organisations adorent les modèles inutilisables
Il existe une raison rarement avouée pour laquelle les organisations tolèrent – voire valorisent – des modèles trop complexes pour être utilisés. Ils ne dérangent rien ni personne.
Un modèle inutilisable :
- ne modifie pas les routines,
- ne redistribue pas les responsabilités,
- ne remet pas en cause les hiérarchies,
- ne produit pas de conflit visible.
Il agit comme un objet de prestige.
On peut dire : « Nous avons un modèle avancé » sans jamais avoir à dire « Nous avons changé notre manière de décider ».
La complexité joue ici un rôle politique. Elle protège le système existant tout en donnant l’illusion du progrès. Comme un panneau travaux en cours posé depuis dix ans. On montre qu’on agit sans jamais transformer la route.
Le mythe dangereux : Plus de données = Meilleure décision
Ce mythe est l’un des plus résistants de l’ère numérique. Il repose sur une confusion majeure entre information et orientation. Un décideur n’a pas besoin de 200 variables.
Il a besoin de :
- savoir quoi regarder,
- savoir quand agir,
- savoir ce qu’il risque s’il se trompe.
Au-delà d’un certain seuil, l’ajout d’informations produit un effet paradoxal :
C’est le syndrome du navigateur GPS qui affiche trop de couches :
- trafic,
- météo,
- radars,
- restaurants,
- travaux,
- avis utilisateurs.
Résultat :
le conducteur ralentit, doute, hésite et finit par prendre la mauvaise sortie.
La bonne modélisation n’est pas additive, elle est sélective.
Le seuil critique : Quand la compréhension humaine décroche
Les sciences cognitives sont formelles. Au-delà de 5 à 7 éléments actifs, la compréhension humaine chute brutalement.
Un modèle à 200 variables peut être compris par :
- son créateur,
- son code,
- et parfois personne d’autre.
À ce stade, il ne s’agit plus de transmission de savoir, mais de délégation aveugle.
Or, dans une organisation, la délégation aveugle est vécue comme une menace. Les utilisateurs ne se disent pas : « Je ne comprends pas ». Ils se disent : « On me demande de suivre quelque chose que je ne maîtrise pas ».
Face à cela, le réflexe humain n’est pas l’adoption, mais la résistance passive.
La vraie fonction d’un modèle : Créer un désaccord fécond
Un bon modèle ne sert pas seulement à prédire. Il sert à structurer le désaccord. Quand un modèle est explicable :
- on peut le contester,
- le discuter,
- le nuancer,
- l’améliorer collectivement.
Quand il est opaque :
- il impose,
- il fige,
- il exclut.
L’exclusion cognitive est alors et toujours suivie d’une exclusion pratique. Les modèles adoptés ne sont pas ceux qui ont raison.
Ce sont ceux qui autorisent la discussion sans humilier.
Le couteau suisse contre la clé plate
Le modèle à 200 variables est un couteau suisse géant. Il fait tout, mais lentement, maladroitement, et personne ne sait quel outil utiliser.
Le modèle à 5 variables est une clé plate :
- un usage clair,
- un geste simple,
- un effet immédiat.
Dans une situation critique, personne ne sort un couteau suisse pour démonter un moteur. On prend l’outil adapté, pas l’outil le plus sophistiqué.
Quand la simplification devient un acte de courage managérial
Réduire un modèle n’est pas un acte technique. C’est un acte politique et managérial.
Cela signifie :
- renoncer à l’exhaustivité,
- accepter une perte de contrôle apparente,
- faire confiance à l’intelligence collective,
- assumer que le modèle ne dira pas tout.
C’est précisément ce renoncement qui rend le modèle utilisable. Dans les organisations matures, la question n’est pas :
« Peut-on modéliser davantage ? »
mais
« Quel est le minimum suffisant pour décider mieux qu’hier ?«
Indicateur clé : Le temps de conversion décisionnelle
Un test simple permet d’évaluer l’utilité réelle d’un modèle :
Temps entre la sortie du modèle et la décision effective.
- Si ce temps augmente : le modèle est un frein.
- S’il diminue : le modèle est un levier.
- S’il n’existe pas : le modèle est décoratif.
La performance d’un modèle ne se mesure pas en AUC mais en secondes gagnées sur la décision.
Ce que cette étude de cas nous apprend (au-delà de la data)
Ce cas n’est pas une histoire de data science.
C’est une leçon générale sur les systèmes humains :
Tout outil qui ne peut pas être approprié sera rejeté.
Tout outil rejeté sera « amélioré » jusqu’à devenir inutilisable.
C’est une loi systémique, pas un accident.
Conclusion : La sobriété comme stratégie systémique
La réduction à 5 variables n’a pas appauvri le modèle. Elle a réintroduit l’humain dans la boucle, et c’est là le cœur de cette étude de cas :
Un système décisionnel n’est performant que lorsqu’il respecte les limites cognitives, politiques et émotionnelles de ceux qui l’utilisent.
La sophistication n’est pas un objectif. En revanche, l’utilité l’est.
Dans les systèmes complexes, la meilleure intervention est souvent celle qui retire, pas celle qui ajoute, et c’est précisément pour cela qu’elle est si difficile à accepter.
A propos de Noos Systemic
Noos Systemic est une plateforme d’investigation dédiée à la modélisation des systèmes de communication et de décision.
Depuis plus de 30 ans, nos travaux portent sur l’analyse des logiques interactives qui façonnent et maintiennent les dynamiques récurrentes au sein des systèmes humains.
Nous ne proposons aucun accompagnement individuel. Cette plateforme constitue une bibliothèque d’investigation dédiée à la compréhension et à la modélisation de ces mécanismes.
Notre approche s’appuie sur le modèle systémique de Palo Alto, une méthodologie d’analyse issue du Mental Research Institute (Californie), conçue pour cartographier les dynamiques relationnelles, décisionnelles et communicationnelles des systèmes humains.
Formation et autorité de recherche
- Mental Research Institute (MRI), Palo Alto, Californie
- Plus de 30 années d’étude et de modélisation
- Plus de 5000 configurations d’interactions humaines documentées
FAQ – Modèles complexes et adoption organisationnelle
1. Si je réduis mon modèle à 5 variables, je perds forcément en précision. N’est-ce pas dangereux ?
C’est la question que tout data scientist pose, et c’est normal.
Réponse courte : Vous ne perdez pas en précision utilisée.
Réponse longue : Un modèle à 200 variables avec 95% de précision qui n’est utilisé que dans 12% des cas a une précision effective de 11,4% (95% × 12%).
Un modèle à 6 variables avec 88% de précision utilisé dans 78% des cas a une précision effective de 68,6% (88% × 78%).
68,6% > 11,4%.
L’adoption multiplie la valeur. La non-adoption annule tout.
2. Comment choisir les 5 bonnes variables parmi 200 ?
Trois critères cumulatifs :
- Explicabilité : peut-on l’expliquer en une phrase à un non-data scientist ?
- Actionnabilité : change-t-on quelque chose si cette variable bouge ?
- Stabilité : la variable est-elle robuste ou ultra-sensible au bruit ?
Commencez par identifier les leviers d’action de l’organisation, puis trouvez les variables qui les mesurent, et non l’inverse.
3. Mon domaine (trading algorithmique, diagnostic médical) exige vraiment 50+ variables. Que faire ?
Deux options :
Option A :
Votre système est automatisé (machine-to-machine). Dans ce cas, gardez la complexité. L’humain n’a pas besoin de comprendre.
Option B :
L’humain doit valider/arbitrer. Dans ce cas, créez une interface à 5 variables synthétiques qui résument les 50 sous-jacentes.
Exemple médical : au lieu d’exposer 50 biomarqueurs, créez 5 scores agrégés (risque cardiovasculaire, fonction rénale, inflammation, etc.).
4. L’équipe data va résister. Comment gérer cette résistance ?
La résistance est normale. Vous demandez à des gens de renoncer à ce qui fonde leur expertise.
Tactique :
Ne présentez pas la simplification comme une réduction, mais comme une traduction.
« On ne supprime pas votre travail. On crée une interface qui permet aux autres de l’utiliser« .
Impliquez l’équipe data dans la conception de l’interface. Donnez-leur le rôle de traducteurs, pas de simplificateurs.
5. Comment mesurer le succès d’un modèle simplifié ?
Oubliez l’AUC. Mesurez :
- Taux d’usage réel (% de décisions qui utilisent le modèle)
- Temps de conversion décisionnelle (délai entre sortie modèle → action)
- Taux de contournement (% de décisions manuelles malgré le modèle)
- Satisfaction utilisateurs (enquête simple : « Ce modèle m’aide-t-il ?« )
Un bon modèle n’est pas celui qui prédit le mieux. C’est celui qui change le plus de décisions.
6. Que faire si mon organisation veut un modèle complexe pour faire sérieux ?
C’est le cas décrit précédemment : la complexité comme objet de prestige.
Tactique :
Proposez un modèle à deux étages :
- Version executive : (complexe, 200 variables) pour les comités et la com’
- Version opérationnelle : (simple, 5 variables) pour les décisions réelles
Laissez la politique se jouer sur la version complexe. Faites tourner l’organisation sur la version simple.
Références
Données empiriques
- Gartner (2022) – « Survey : 80% of Executives Think Automation Can Be Applied to Any Business Decision« . Gartner Newsroom, août 2022.
- Gartner (2024) – « Gartner Survey Finds Generative AI Is Now the Most Frequently Deployed AI Solution in Organizations«
Sciences cognitives
- Miller, G.A. (1956) – « The Magical Number Seven, Plus or Minus Two : Some Limits on Our Capacity for Processing Information« . Psychological Review, 63(2), 81-97.
- Cowan, N. (2001) – « The magical number 4 in short-term memory : A reconsideration of mental storage capacity« . Behavioral and Brain Sciences, 24(1), 87-114.
Approche systémique (Palo Alto)
- Watzlawick, P., Weakland, J., & Fisch, R. (1974) – « Change: Principles of Problem Formation and Problem Resolution« . New York: W.W. Norton.
- Bateson, G. (1972) – « Steps to an Ecology of Mind« . University of Chicago Press.
Adoption des technologies
- Rogers, E.M. (2003) – « Diffusion of Innovations (5th ed.)« . New York: Free Press.
- Davis, F.D. (1989) – « Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology« . MIS Quarterly, 13(3), 319-340.
Cet article résonne avec votre réalité ? Partagez-le !
Vous êtes CDO, data scientist, ou manager ?
Ces analyses vous concernent directement.
Découvrez d’autres analyses systémiques sur Noos Systemic où nous identifions et analysons les boucles invisibles qui structurent (et paralysent) nos organisations.